Generative AI, in particular Large Language Models (LLMs) like ChatGPT and Bing Chat (and its evil alter ego, Sydney), have raised a lot of important questions about the nature of intelligence, language, and the future of knowledge work.
I can’t answer any of them.
I can, however, talk about Section 230! To cut to the chase, Section 230 of the Communications Decency Act does not protect generative AI in general, including LLMs. Moreover, it shouldn’t. LLMs are being rushed to market despite their well-known risks. Without a more comprehensive legal framework to oversee and regulate AI technology, one of the only checks we have on reckless behavior and dangerous products is tort law: the courts. If Section 230 or some new law shielded LLMs, it would mean that others, including society as a whole, would bear the costs of their new and barely tested technology, while tech companies reap the benefits. Liability shields are useful in some circumstances, but not this one, and not now.
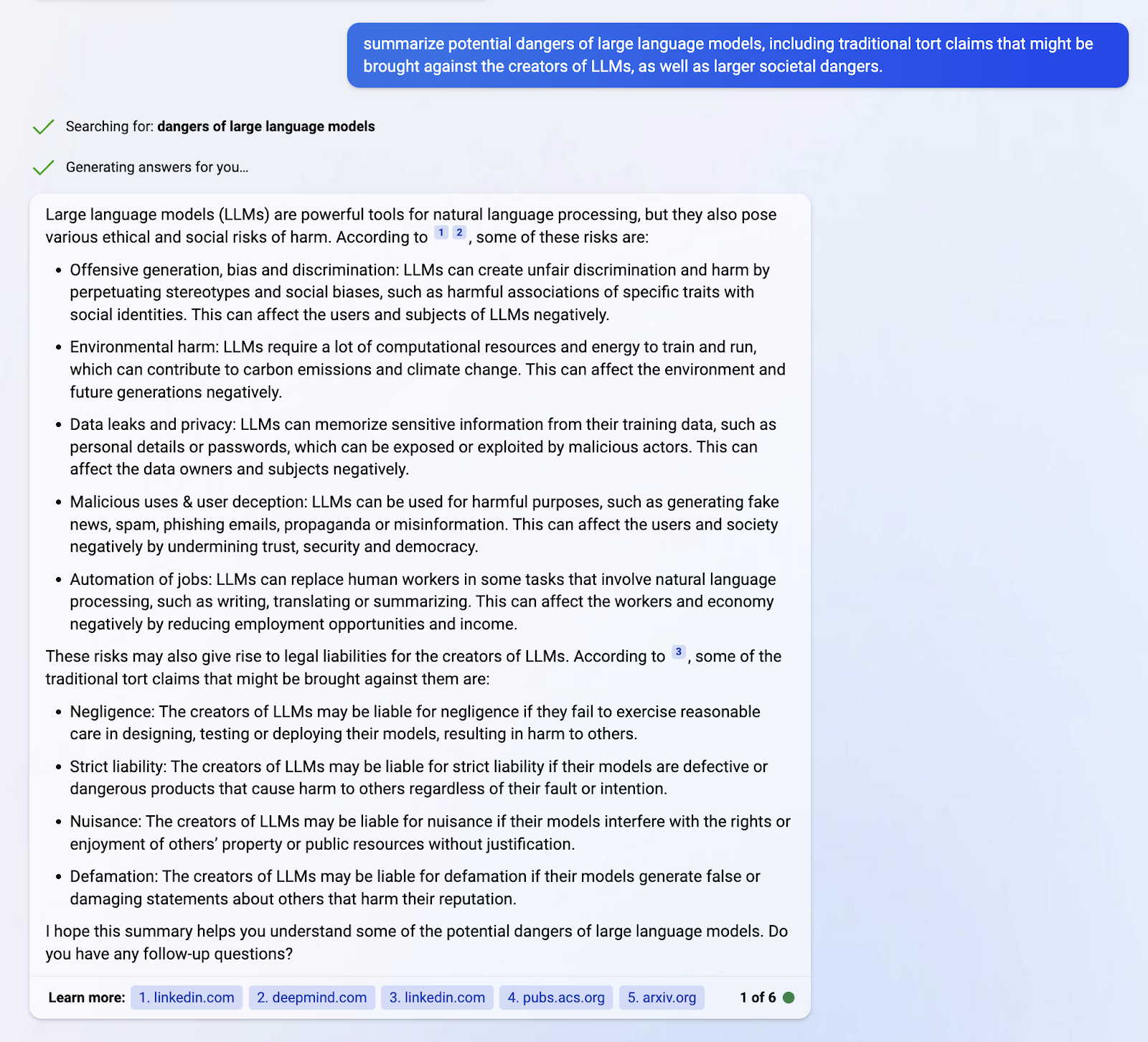
I’ll just let Bing summarize the dangers of LLMs:
Section 230 allows platforms to publish third-party content, such as posts, images, and video from users, without facing the traditional legal liabilities that publishers face, such as defamation. They are still liable for their own words and actions. Section 230 (and the First Amendment!) allows them to do things like moderate content, organize and recommend user content to other users, as well as host content. This is not because these are things that “publishers” do – Section 230 does not protect “publishers” as a class. It protects publishing, and all of those things are simply part of what it means to “publish” material.
In our recent brief in the Gonzalez case at the Supreme Court, we made that point with significantly more detail. (Notably, Justice Gorsuch raised the question of AI and Section 230 during oral argument.) A clear understanding of what Section 230 protects also makes clear what it does not. For example, it does not allow online marketplaces to escape liability for selling dangerous products even if the product listing was created by a third party. “Selling” is not “publishing.” Section 230 is not a deregulatory charter for the internet that allows any company that in some way interacts with third-party content to ignore state and local laws or escape liability for the harms they create that are outside Section 230’s narrow, but important, scope. Section 230 is a good law because it promotes free expression and enables valuable services that could not exist without it. The case for extending it to LLMs has simply not been made, and the default rules for new technology should simply be the default rules that we already have: that companies have a general duty of care and can be held liable for the harms they create and the costs they impose on others.
As a legal matter, the companies that deploy LLMs are not protected by Section 230 for at least two reasons. First, they don’t merely publish, or republish, content from other sources. They generate their own new content using neural networks that were trained on user content. That is very different. Their output is new information – content that so transforms the input material that is in their training sets that viewing LLMs as merely publishers of third-party content seems, frankly, disingenuous. You don’t need millions of dollars worth of GPUs for that. At most, it might be fair to say that the authors of the content in a training set, the company that creates an LLM, and maybe the user interacting with the LLM are all somehow co-creators of the LLM’s output – which still means that Section 230 does not apply. Content that a service helps develop “in whole or in part” is outside Section 230’s scope.
Section 230 also does not allow services to use uprooted facts or data and then escape liability by saying the data came from somewhere else. It is not an “I read it on the internet so don’t blame me!” statute. Section 230 protects users in the same way that it protects platforms like YouTube, and seeing why the “information” and “information content” that 230 protects must in some way relate to publishing (or republishing, which makes no legal difference) actual user content is easier in the user context. For example, if I trawl around YouTube watching Q-Anon and anti-vax videos (note: I do not actually do this) and then I create my own video repeating the dangerous, defamatory, or otherwise actionable material I saw, of course I am liable for the content of my video. I can’t say, “Not my fault, I learned it on YouTube!” The same applies to services. While 230 does not require that third-party content be somehow labeled in a specific way, or presented in full or verbatim, LLMs show how dangerous maximalist interpretations of Section 230 can be. It should not be controversial that companies should be responsible for the harms they create and the costs they impose on others. Narrow liability shields can be justified in some circumstances, but they have not been for LLMs.
Professor Matt Perault has argued in Lawfare that LLMs should have some sort of liability protection. I recommend that everyone read his thoughtful piece in full, and I am happy that he and I agree that Section 230 as written does not protect LLMs. But he argues that Section 230 should be amended to cover them, at least in part. He writes: “If a company that deploys an LLM can be dragged into lengthy, costly litigation any time a user prompts the tool to generate text that creates legal risk, companies will narrow the scope and scale of deployment dramatically.” He also writes that “With such legal risk, platforms would deploy LLMs only in situations where they could bear the potential costs.” He acknowledges that many people would view that as a good thing. I am one of them, even though I agree with some of his observations. It’s true that large companies like Microsoft can better bear litigation costs than small companies, and that liability shields can promote competition. This is true of most tort claims. National restaurants can probably better afford to defend themselves if they are sued for food poisoning. We should not respond to this by making it easier for small businesses to poison people. Similarly, we also don’t need a new legal regime that allows more potentially dangerous AI products and features to come to market.
Some of the harms that LLMs might create are purely speculative. And so are the benefits. I have used ChatGPT a little, and once I got it to rewrite an awkward sentence I was struggling with into something better. That was pretty cool, but mostly it seems like a fun toy. I have read about how some people are using LLMs for genuinely useful things, like doctors appealing insurance claims rejections. (Perhaps the insurance companies are also working on using LLMs to deny appeals.) But after using the new Bing for a while, I am skeptical that it’s an improvement on traditional search – at least in its chat interface. It’s possible that if the benefits of LLMs become apparent and it seems like they are being held back by frivolous litigation costs, then we can revisit what liability looks like for AI. In the meantime, immunizing companies rushing LLMs to market is as (or more) likely to shield reckless behavior as to enable beneficial new products.